De Novo Genome Assembly
Key Learning Outcomes
After completing this practical the trainee should be able to:
-
Compile velvet with appropriate compile-time parameters set for a specific analysis
-
Be able to choose appropriate assembly parameters
-
Assemble a set of paired-end reads from a single insert-size library
-
Be able to visualise an assembly in AMOS Hawkeye
Resources You’ll be Using
Although we have provided you with an environment which contains all the tools and data you will be using in this module, you may like to know where we have sourced those tools and data from.
Tools Used
Velvet:
http://www.ebi.ac.uk/~zerbino/velvet/
AMOS Hawkeye:
http://apps.sourceforge.net/mediawiki/amos/index.php?title=Hawkeye
gnx-tools:
https://github.com/mh11/gnx-tools
FastQC:
http://www.bioinformatics.bbsrc.ac.uk/projects/fastqc/
Sources of Data
-
ftp://ftp.sra.ebi.ac.uk/vol1/fastq/SRR022/SRR022852/SRR022852_1.fastq.gz
-
ftp://ftp.sra.ebi.ac.uk/vol1/fastq/SRR022/SRR022852/SRR022852_2.fastq.gz
-
ftp://ftp.sra.ebi.ac.uk/vol1/fastq/SRR023/SRR023408/SRR023408_1.fastq.gz
-
ftp://ftp.sra.ebi.ac.uk/vol1/fastq/SRR023/SRR023408/SRR023408_2.fastq.gz
Introduction
The aim of this module is to become familiar with performing de novo genome assembly using Velvet, a de Bruijn graph based assembler, on a variety of sequence data.
Prepare the Environment
The first exercise should get you a little more comfortable with the computer environment and the command line.
First make sure that you are in the denovo working directory by typing:
cd /home/trainee/denovo
and making absolutely sure you’re there by typing:
pwd
Now create sub-directories for this and the two other velvet practicals. All these directories will be made as sub-directories of a directory for the whole course called NGS. For this you can use the following commands:
mkdir -p NGS/velvet/{part1,part2}
The -p tells mkdir (make directory) to make any parent directories
if they don’t already exist. You could have created the above
directories one-at-a-time by doing this instead:
mkdir NGS
mkdir NGS/velvet
mkdir NGS/velvet/part1
mkdir NGS/velvet/part2
After creating the directories, examine the structure and move into the directory ready for the first velvet exercise by typing:
ls -R NGS
cd NGS/velvet/part1
pwd
Downloading and Compiling Velvet
For the duration of this workshop, all the software you require has been set up for you already. This might not be the case when you return to “real life”. Many of the programs you will need, including velvet, are quite easy to set up, it might be instructive to try a couple.
Although you will be using the preinstalled version of velvet, it is useful to know how to compile velvet as some of the parameters you might like to control can only be set at compile time. You can find the latest version of velvet at:
http://www.ebi.ac.uk/~zerbino/velvet/
You could go to this URL and download the latest velvet version, or equivalently, you could type the following, which will download, unpack, inspect, compile and execute your locally compiled version of velvet:
cd /home/trainee/denovo/NGS/velvet/part1
pwd
tar xzf /home/trainee/denovo/data/velvet_1.2.10.tgz
ls -R
cd velvet_1.2.10
make
./velveth
The standout displayed to screen when ’make’ runs may contain an error message but it is ignored
Take a look at the executables you have created. They will be displayed as green by the command:
ls --color=always
The switch –color, instructs that files be coloured according to their
type. This is often the default but we are just being explicit. By
specifying the value always, we ensure that colouring is always
applied, even from a script.
Have a look of the output the command produces and you will see that
MAXKMERLENGTH=31 and CATEGORIES=2 parameters were passed into the
compiler.
This indicates that the default compilation was set for de Bruijn graph k-mers of maximum size 31 and to allow a maximum of just 2 read categories. You can override these, and other, default configuration choices using command line parameters. Assume, you want to run velvet with a k-mer length of 41 using 3 categories, velvet needs to be recompiled to enable this functionality by typing:
make clean
make MAXKMERLENGTH=41 CATEGORIES=3
./velveth
Discuss with the persons next to you the following questions:
Question
What are the consequences of the parameters you have given make for velvet?
Answer
MAXKMERLENGTH: increase the max k-mer length from 31 to 41
CATEGORIES: paired-end data require to be put into separate categories. By increasing this parameter from 2 to 3 allows you to process 3 paired / mate-pair libraries and unpaired data.
Question
Why does Velvet use k-mer 31 and 2 categories as default?
Answer
Possibly a number of reason:
1) odd number to avoid palindromes
2) The first reads were very short (20-40 bp) and there were hardly any paired-end data around so there was no need to allow for longer k-mer lengths / more categories.
3) For programmers: 31 bp get stored in 64 bits (using 2bit encoding)
Question
Should you get better results by using a longer k-mer length?
Answer
If you can achieve a good k-mer coverage - yes.
Question
What effect would the following compile-time parameters have on velvet: OPENMP=Y
Answer
Turn on multithreading
Question
LONGSEQUENCES=Y
Answer
Assembling reads / contigs longer than 32kb long
Question
BIGASSEMBLY=Y
Answer
Using more than 2.2 billion reads
Question
SINGLE_COV_CAT=Y
Answer
Merge all coverage statistics into a single variable - save memory
For a further description of velvet compile and runtime parameters please see the velvet Manual: https://github.com/dzerbino/velvet/wiki/Manual
Assembling Paired-end Reads using Velvet
The use of paired-end data in de novo genome assembly results in better quality assemblies, particularly for larger, more complex genomes. In addition, paired-end constraint violation (expected distance and orientation of paired reads) can be used to identify misassemblies.
If you are doing de novo assembly, pay the extra and get paired-ends: they’re worth it!
The data you will examine in this exercise is again from Staphylococcus aureus which has a genome of around 3MBases. The reads are Illumina paired end with an insert size of ~350 bp.
The required data can be downloaded from the SRA. Specifically, the run data (SRR022852) from the SRA Sample SRS004748.
The following exercise focuses on preparing the paired-end FASTQ files ready for Velvet, using Velvet in paired-end mode and comparing results with Velvet’s ’auto’ option.
First move to the directory you made for this exercise and make a suitable named directory for the exercise:
cd /home/trainee/denovo/NGS/velvet/part2
mkdir SRS004748
cd SRS004748
There is no need to download the read files, as they are already stored locally. You will simply create a symlink to this pre-downloaded data using the following commands:
ln -s /home/trainee/denovo/data/SRR022852_?.fastq.gz ./
It is interesting to monitor the computer’s resource utilisation, particularly memory. A simple way to do this is to open a second terminal and in it type:
top
top is a program that continually monitors all the processes running
on your computer, showing the resources used by each. Leave this running
and refer to it periodically throughout your Velvet analyses.
Particularly if they are taking a long time or whenever your curiosity
gets the better of you. You should find that as this practical
progresses, memory usage will increase significantly.
Now, back to the first terminal, you are ready to run velveth and
velvetg. The reads are -shortPaired and for the first run you should
not use any parameters for velvetg.
From this point on, where it will be informative to time your runs. This
is very easy to do, just prefix the command to run the program with the
command time. This will cause UNIX to report how long the program took
to complete its task.
Set the two stages of velvet running, whilst you watch the memory usage
as reported by top. Time the velvetg stage:
velveth run_25 25 -fmtAuto -create_binary -shortPaired -separate SRR022852_1.fastq.gz SRR022852_2.fastq.gz
time velvetg run_25
Question
What does -fmtAuto and -create_binary do? (see help menu)
Answer
-fmtAuto tries to detect the correct format of the input files e.g. FASTA, FASTQ and whether they are compressed or not.
-create_binary outputs sequences as a binary file. That means that velvetg can read the sequences from the binary file more quickly that from the original sequence files.
Question
Comment on the use of memory and CPU for velveth and velvetg?
Answer
velveth uses only one CPU while velvetg uses all possible CPUs for some parts of the calculation.
Question
How long did velvetg take?
Answer
My own measurements are:
real 1m8.877s; user 4m15.324s; sys 0m4.716s
Next, after saving your contigs.fa file from being overwritten, set
the cut-off parameters that you investigated in the previous exercise
and rerun velvetg. time and monitor the use of resources as
previously. Start with -cov_cutoff 16 thus:
mv run_25/contigs.fa run_25/contigs.fa.0
time velvetg run_25 -cov_cutoff 16
Up until now, velvetg has ignored the paired-end information. Now try
running velvetg with both -cov_cutoff 16 and -exp_cov 26, but
first save your contigs.fa file. By using -cov_cutoff and
-exp_cov, velvetg tries to estimate the insert length, which you
will see in the velvetg output. The command is, of course:
mv run_25/contigs.fa run_25/contigs.fa.1
time velvetg run_25 -cov_cutoff 16 -exp_cov 26
Question
Comment on the time required, use of memory and CPU for velvetg?
Answer
Runtime is lower when velvet can reuse previously calculated data. By using -exp_cov, the memory usage increases.
Question
Which insert length does Velvet estimate?
Answer
Paired-end library 1 has length: 228, sample standard deviation: 26
Next try running velvetg in ‘paired-end mode‘. This entails running
velvetg specifying the insert length with the parameter -ins_length
set to 350. Even though velvet estimates the insert length it is always
advisable to check / provide the insert length manually as velvet can
get the statistics wrong due to noise. Just in case, save your last
version of contigs.fa. The commands are:
mv run_25/contigs.fa run_25/contigs.fa.2
time velvetg run_25 -cov_cutoff 16 -exp_cov 26 -ins_length 350
mv run_25/contigs.fa run_25/contigs.fa.3
Question
How fast was this run?
Answer
My own measurements are:
real 0m29.792s; user 1m4.372s; sys 0m3.880s
Take a look into the Log file.
Question
What is the N50 value for the velvetg runs using the switches
Answer
Base run: 19,510 bp
-cov_cutoff 16: 24,739 bp
-cov_cutoff 16 -exp_cov 26: 61,793 bp
-cov_cutoff 16 -exp_cov 26 -ins_length 350: n50 of 62,740 bp; max 194,649 bp; total 2,871,093 bp
Try giving the -cov_cutoff and/or -exp_cov parameters the value
auto. See the velvetg help to show you how. The information Velvet
prints during running includes information about the values used
(coverage cut-off or insert length) when using the auto option.
Question
What coverage values does Velvet choose (hint: look at the output that Velvet produces while running)?
Answer
Median coverage depth = 26.021837
Removing contigs with coverage < 13.010918 …
Question
How does the N50 value change?
Answer
n50 of 68,843 bp; max 194,645 bp; total 2,872,678 bp
Run gnx on all the contig.fa files you have generated in the course
of this exercise. The command will be:
gnx -min 100 -nx 25,50,75 run_25/contigs.fa*
Question
For which runs are there Ns in the contigs.fa file and why?
Answer
contigs.fa.2, contigs.fa.3, contigs.fa
Velvet tries to use the provided (or infers) the insert length and fills ambiguous regions with Ns.
Comment on the number of contigs and total length generated for each run.
| Filename | No. contigs | Total length | No. Ns |
|---|---|---|---|
| Contigs.fa.0 | 631 | 2,830,659 | 0 |
| Contigs.fa.1 | 580 | 2,832,670 | 0 |
| Contigs.fa.2 | 166 | 2,849,919 | 4,847 |
| Contigs.fa.3 | 166 | 2,856,795 | 11,713 |
| Contigs.fa | 163 | 2,857,439 | 11,526 |
AMOS Hawkeye
We will now output the assembly in the AMOS massage format and visualise the assembly using AMOS Hawkeye.
Run velvetg with appropriate arguments and output the AMOS message
file, then convert it to an AMOS bank and open it in Hawkeye:
time velvetg run_25 -cov_cutoff 16 -exp_cov 26 -ins_length 350 -amos_file yes -read_trkg yes
time bank-transact -c -b run_25/velvet_asm.bnk -m run_25/velvet_asm.afg
hawkeye run_25/velvet_asm.bnk
Looking at the scaffold view of a contig, comment on the proportion of “happy mates” to “compressed mates” and “stretched mates”.
Nearly all mates are compressed with no stretched mates and very few happy mates.
Question
What is the mean and standard deviation of the insert size reported under the Libraries tab?
Answer
Mean: 350 bp SD: 35 bp
Question
Look at the actual distribution of insert sizes for this library. Can you explain where there is a difference between the mean and SD reported in those two places?
Answer
We specified -ins_length 350 to the velvetg command. Velvet uses this value, in the AMOS message file that it outputs, rather than its own estimate.
You can get AMOS to re-estimate the mean and SD of insert sizes using intra-contig pairs. First, close Hawkeye and then run the following commands before reopening the AMOS bank to see what has changed.
asmQC -b run_25/velvet_asm.bnk -scaff -recompute -update -numsd 2
hawkeye run_25/velvet_asm.bnk
Looking at the scaffold view of a contig, comment on the proportion of “happy mates” to “compressed mates” and “stretched mates”.
There are only a few compressed and stretched mates compared to happy mates. There are similar numbers of stretched and compressed mates.
Question
What is the mean and standard deviation of the insert size reported under the Libraries tab?
Answer
Mean: 226 bp SD: 25 bp
Question
Look at the actual distribution of insert sizes for this library. Does the mean and SD reported in both places now match?
Answer
Yes
Question
Can you find a region with an unusually high proportion of stretched, compressed, incorrectly orientated or linking mates? What might this situation indicate?
Answer
This would indicate a possible misassembly and worthy of further investigation.
Look at the largest scaffold, there are stacks of stretched pairs which span contig boundaries. This indicates that the gap size has been underestimated during the scaffolding phase.
Velvet and Data Quality
So far we have used the raw read data without performing any quality control or read trimming prior to doing our velvet assemblies.
Velvet does not use quality information present in FASTQ files.
For this reason, it is vitally important to perform read QC and quality trimming. In doing so, we remove errors/noise from the dataset which in turn means velvet will run faster, will use less memory and will produce a better assembly. Assuming we haven’t compromised too much on coverage.
To investigate the effect of data quality, we will use the run data (SRR023408) from the SRA experiment SRX008042. The reads are Illumina paired end with an insert size of 92 bp.
Go back to the main directory for this exercise and create and enter a new directory dedicated to this phase of the exercise. The commands are:
cd /home/trainee/denovo/NGS/velvet/part2
mkdir SRX008042
cd SRX008042
Create symlinks to the read data files that we downloaded for you from the SRA:
ln -s /home/trainee/denovo/data/SRR023408_?.fastq.gz ./
We will use FastQC, a tool you should be familiar with, to visualise the quality of our data. We will use FastQC in the Graphical User Interface (GUI) mode.
Start FastQC and set the process running in the background, by using a
trailing &, so we get control of our terminal back for entering more
commands:
fastqc &
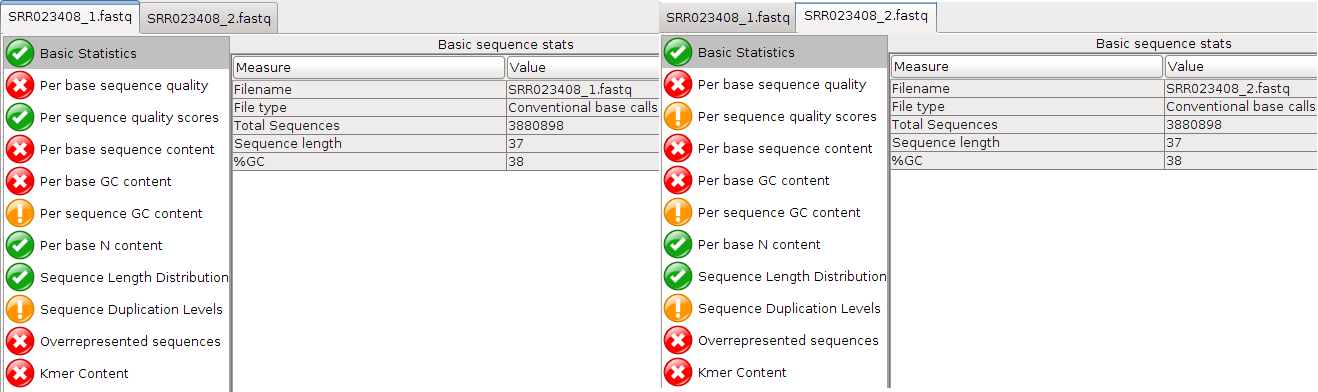
Open the two compressed FASTQ files (File -> Open) by selecting them both and clicking OK). Look at tabs for both files:
Question
Are the quality scores the same for both files?
Answer
Overall yes
Question
Which value varies?
Answer
Per sequence quality scores
Question
Take a look at the Per base sequence quality for both files. Did you note that it is not good for either file?
Answer
The quality score of both files drop very fast. Qualities of the REV strand drop faster than the FWD strand. This is because the template has been sat around while the FWD strand was sequenced.
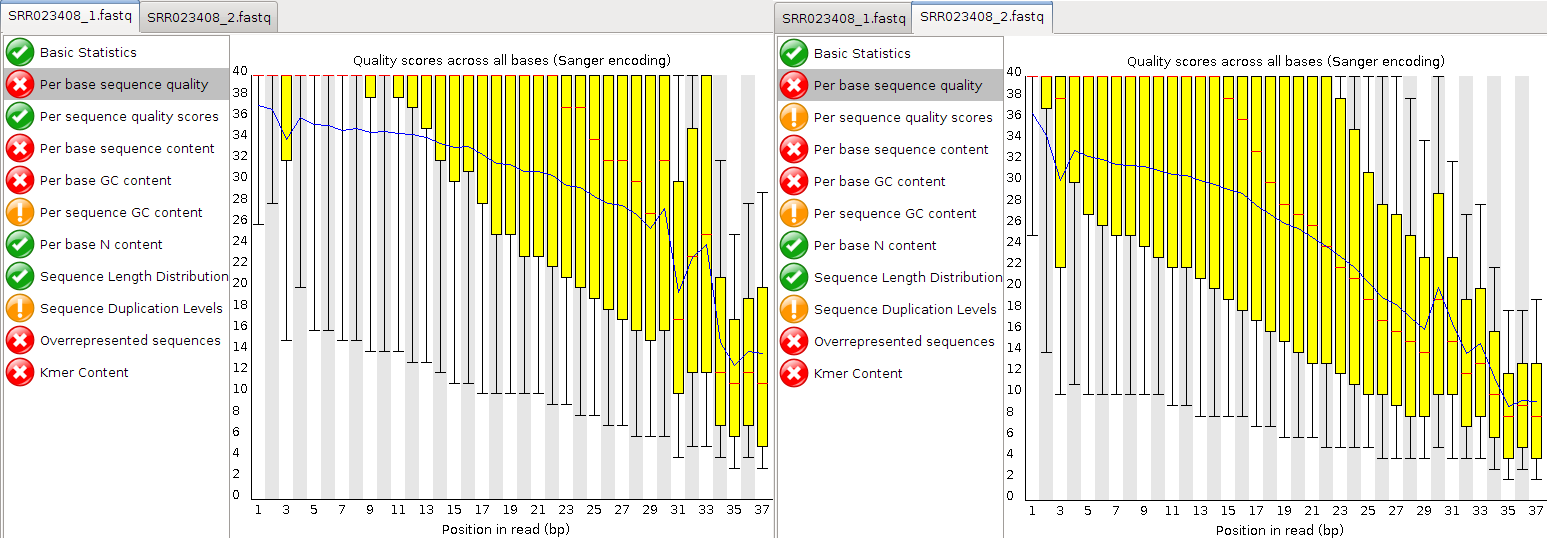
Question
At which positions would you cut the reads if we did “fixed length trimming”?
Answer
Looking at the “Per base quality” and “Per base sequence content”, I would choose around 27
Question
Why does the quality deteriorate towards the end of the read?
Answer
Errors more likely for later cycles
Question
Does it make sense to trim the 5’ start of reads?
Answer
Looking at the “Per base sequence content”, yes - there is a clear signal at the beginning.
Have a look at the other options that FastQC offers.
Question
Which other statistics could you use to support your trimming strategy?
Answer
“Per base sequence content”, “Per base GC content”, “Kmer content”, “Per base sequence quality”
Once you have decided what your trim points will be, close FastQC. We
will use fastx_trimmer from the FASTX-Toolkit to perform fixed-length
trimming. For usage information see the help:
fastx_trimmer -h
fastx_trimmer is not able to read compressed FASTQ files, so we first
need to decompress the files ready for input.
The suggestion (hopefully not far from your own thoughts?) is that you trim your reads as follows:
gunzip < SRR023408_1.fastq.gz > SRR023408_1.fastq
gunzip < SRR023408_2.fastq.gz > SRR023408_2.fastq
fastx_trimmer -Q 33 -f 1 -l 32 -i SRR023408_1.fastq -o SRR023408_trim1.fastq
fastx_trimmer -Q 33 -f 1 -l 27 -i SRR023408_2.fastq -o SRR023408_trim2.fastq
Many NGS read files are large. This means that simply reading and writing files can become the bottleneck, also known as I/O bound. Therefore, it is often good practice to avoid unnecessary disk read/write.
Tips
We could do what is called pipelining to send a stream of data from one command to another, using the pipe (|) character, without the need for intermediary files. The following command would achieve this:
gunzip –to-stdout < SRR023408_1.fastq.gz | fastx_trimmer -Q 33 -f 4 -l 32 -o SRR023408_trim1.fastq
gunzip –to-stdout < SRR023408_2.fastq.gz | fastx_trimmer -Q 33 -f 3 -l 29 -o SRR023408_trim2.fastq
Now run velveth with a k-mer value of 21 for both the untrimmed and
trimmed read files in -shortPaired mode. Separate the output of the
two executions of velveth into suitably named directories, followed by
velvetg:
# untrimmed reads
velveth run_21 21 -fmtAuto -create_binary -shortPaired -separate SRR023408_1.fastq SRR023408_2.fastq
time velvetg run_21
# trimmed reads
velveth run_21trim 21 -fmtAuto -create_binary -shortPaired -separate SRR023408_trim1.fastq SRR023408_trim2.fastq
time velvetg run_21trim
Question
How long did the two velvetg runs take?
Answer
run_25: real 3m16.132s; user 8m18.261s; sys 0m7.317s
run_25trim: real 1m18.611s; user 3m53.140s; sys 0m4.962s
Question
What N50 scores did you achieve?
Answer
Untrimmed: 11
Trimmed: 15
Question
What were the overall effects of trimming?
Answer
Time saving, increased N50, reduced coverage
The evidence is that trimming improved the assembly. The thing to do
surely, is to run velvetg with the -cov_cutoff and -exp_cov. In
order to use -cov_cutoff and -exp_cov sensibly, you need to
investigate with R, as you did in the previous exercise, what parameter
values to use. Start up R and produce the weighted histograms:
R --no-save
library(plotrix)
data <-read.table("run_21/stats.txt", header=TRUE)
data2 <- read.table("run_21trim/stats.txt", header=TRUE)
par(mfrow=c(1,2))
weighted.hist(data$short1_cov, data$lgth, breaks=0:50)
weighted.hist(data2$short1_cov, data2$lgth, breaks=0:50)
Weighted k-mer coverage histograms of the paired-end reads pre-trimmed (left) and post-trimmed (right).
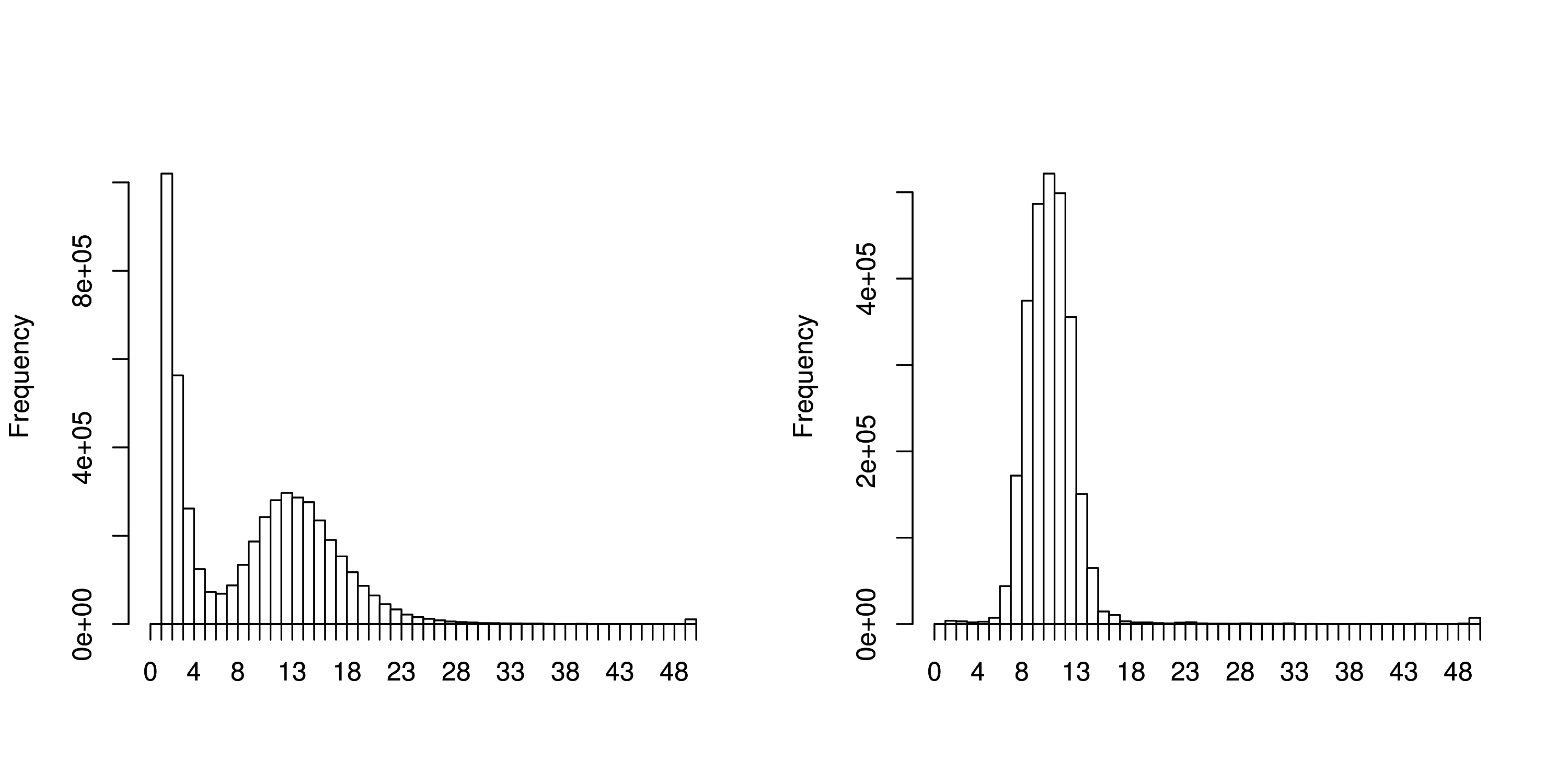
For the untrimmed read histogram (left) there is an expected coverage of around 13 with a coverage cut-off of around 7. For the trimmed read histogram (right) there is an expected coverage of around 9 with a coverage cut-off of around 5.
If you disagree, feel free to try different settings, but first quit R
before running velvetg:
q()
time velvetg run_21 -cov_cutoff 7 -exp_cov 13 -ins_length 92
time velvetg run_21trim -cov_cutoff 5 -exp_cov 9 -ins_length 92
Question
How good does it look now?
Answer
Still not great
Runtime: Reduced runtime
Memory: Lower memory usage
Question
K-mer choice (Can you use k-mer 31 for a read of length 30 bp?)
Answer
K-mer has to be lower than the read length and the K-mer coverage should be sufficient to produce results.
Question
Does less data mean “worse” results?
Answer
Not necessarily. If you have lots of data you can safely remove poor data without too much impact on overall coverage.
Compare the results, produced during the last exercises, with each other,
| Metric | SRR023408 | SRR023408.trimmed |
|---|---|---|
| Overall Quality (1-5) | 5 | 4 |
| bp Coverage | 95x (37bp; 7761796) | 82x (32bp; 7761796) |
| k-mer Coverage | 43x (21); 33x (25) | 30x (21); 20.5x (25) |
| N50 (k-mer used) | 2,803 (21) | 2,914 (21) |
Question
What would you consider as the “best” assembly?
Answer
SRR023408.trimmed
Question
If you found a candidate, why do you consider it as “best” assembly?
Answer
Overall data quality and coverage
Question
How else might you assess the the quality of an assembly?
Hint
Hawkeye
Answer
By trying to identify paired-end constraint violations using AMOS Hawkeye.